FiberMall has extrapolated the AI infrastructure including optical transceivers that ChatGPT brings to the table.
The difference from a traditional data center is that with the InfiniBand fat tree structure common to AI, more switches are used and the number of ports upstream and downstream at each node is identical.
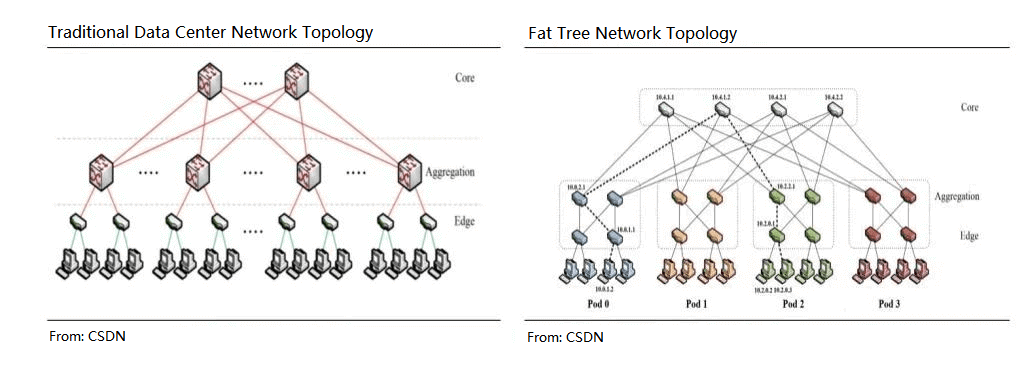
One of the basic units corresponding to the AI clustering model used by NVIDIA is the SuperPOD.
A standard SuperPOD is built with 140 DGX A100 GPU servers, HDR InfiniBand 200G NICs, and 170 NVIDIA Quantum QM8790 switches with 200G and 40 ports each.
Based on the NVIDIA solution, a SuperPOD with 170 switches, each switch has 40 ports, and the simplest way is to interconnect 70 servers each, and the corresponding cable requirement is 40×170/2=3400 ports, considering the actual deployment situation up to 4000 cables. Among them, the ratio of copper cable: AOC: optical module = 4:4:2, corresponding to the number of optical transceivers required = 4000 * 0.2 * 2 = 1600, that is, for a SuperPod, the ratio of server: switch: optical module usage = 140: 170: 1600 = 1: 1.2: 11.4
A requirement similar to GPT4.0 entry-level requirements requires approximately 3750 NVIDIA DGX A100 servers. The requirements of optical transceivers under this condition are listed in the following table.

FiberMall extrapolates the demand for servers, switches, and optical transceivers from AI data center architecture. In this extrapolation process, FiberMall uses the ratio of 4:4:2. The use of optical modules in the data center is ultimately directly related to traffic demand. This ratio is likely to exist only at full capacity, and it is still worthwhile to study in depth how the service traffic within the AI data center is now.
https://www.fibermall.com/blog/how-many-optical-transceivers-does-chatgpt-require.htm


